

Les précédents articles de cette série vous ont permis d’identifier les risques pesant sur votre système d’information et de définir les objectifs de reprise à atteindre. Reste désormais à répondre à la question cruciale : « quelles solutions mettre en œuvre ? »
Il n’existe pas de solution universelle en matière de PCA ou de PRA. Les choix techniques dépendent avant tout des RTO, des RPO et des scénarios de sinistre identifiés lors des étapes précédentes. De la même manière, il n’existe pas de stratégie miracle capable de répondre à tous les besoins. Plusieurs approches sont possibles, mais pour construire un dispositif cohérent, j’ai choisi d’aborder le sujet par couches de résilience.
La liste qui va suivre n’est évidemment pas exhaustive, mais elle présente les principales solutions à envisager dans le cadre d’un PCA/PRA. Accrochez-vous bien, on est parti pour un long voyage !
🧯 Sécuriser les infrastructures physiques
🎯 Comment éviter que l’environnement ne rende mon infrastructure indisponible ?
Avant même de s’intéresser aux serveurs, aux applications ou aux données, il convient de sécuriser l’environnement qui les héberge. La disponibilité d’un système d’information dépend autant de ses équipements que des infrastructures physiques sur lesquelles ils reposent. L’objectif de cette première couche de résilience est simple : limiter les risques qu’un incident affectant les locaux ou les infrastructures techniques ne provoque une interruption de service.
Selon la criticité des activités concernées, vous pouvez opter pour une ou plusieurs des mesures suivantes :
- sécurisation des accès aux locaux techniques (badge, biométrie, vidéosurveillance) ;
- protection électrique (onduleurs, groupes électrogènes, alimentations redondées) ;
- maîtrise des conditions environnementales (température, humidité, climatisation) ;
- détection et extinction incendie ;
- protection contre les dégâts des eaux ;
🖥️ Éliminer les points de défaillance matériels
🎯 Comment maintenir un service lorsqu’un équipement tombe en panne ?
Après avoir sécurisé l’environnement qui héberge votre système d’information, il convient de s’intéresser aux équipements eux-mêmes. Même dans une infrastructure parfaitement protégée, une panne matérielle reste inévitable : disque dur défectueux, alimentation hors service, serveur indisponible, défaillance d’une baie de stockage ou d’un équipement réseau, etc.
L’objectif de cette deuxième couche de résilience est donc d’éliminer autant que possible les points uniques de défaillance (Single Point of Failure ou SPOF). Lorsqu’un équipement critique devient indisponible, son remplacement ou son basculement doit pouvoir s’effectuer sans interruption majeure de l’activité.
Redonder les composants critiques
Une première approche consiste à éliminer les points uniques de défaillance à l’intérieur même des équipements. Certains matériels intègrent aujourd’hui des mécanismes de redondance tels que :
- Alimentations électriques doubles ;
- Contrôleurs de stockage redondants ;
- Interfaces réseau multiples ;
- Disques configurés en RAID ;
- Ventilateurs redondés.
Ils permettent à un composant de tomber en panne sans rendre l’équipement indisponible. Ils constituent donc un critère de choix essentiel pour l’achat d’équipements critiques de votre infrastructure. Cette démarche améliore la disponibilité mais ne protège pas contre la perte complète d’un serveur, d’une baie ou d’un équipement réseau.
Prévoir la défaillance d’un équipement complet
Lorsque les objectifs de reprise sont plus exigeants, il devient nécessaire d’aller au-delà de la simple redondance interne en misant sur des équipements à même de prendre automatiquement le relais lorsqu’un autre devient indisponible. Plusieurs solutions peuvent alors être envisagées, comme par exemple :
- Clusters de serveurs ;
- Hyperviseurs mutualisés ;
- Répartition de charge ;
- Paires de firewall en haute disponibilité ;
- Empilement ou redondance des commutateurs.
Le principal avantage de la redondance matérielle est la réduction drastique du temps d’interruption. Mais en contrepartie, elle implique généralement des coûts d’acquisition, d’exploitation et de maintenance plus élevés.
Stock de secours ou haute disponibilité ?
Toutes les entreprises n’ont pas besoin d’une infrastructure entièrement redondée. Pour certains équipements, conserver un stock de pièces détachées ou un matériel de remplacement peut constituer une alternative pertinente. Il peut par exemple être judicieux de disposer d’alimentations de rechange, de disques de remplacement, de modules SFP, d’un commutateur ou d’un firewall prêt à être déployé. Le choix entre stock de secours et haute disponibilité va principalement dépendre :
- Du coût d’une interruption ;
- Du délai de remplacement ;
- Des compétences internes pour la réparation et remise en état de marche ;
- Des objectifs de reprise fixés.
S’appuyer sur les bons contrats de maintenance
Pour finir, la résilience ne repose pas uniquement sur la technologie. Les contrats de support constructeurs jouent également un rôle important dans la stratégie de continuité.
Selon la criticité des équipements, et les RTO définis, il peut être intéressant de prévoir :
- Des interventions sous SLA (H+4, J+1, J+5, etc) ;
- Un remplacement anticipé des équipements vieillissants ;
- Une assistance constructeur renforcée.
🛜 Garantir la continuité du réseau
🎯 Comment maintenir la connectivité lorsque le réseau devient le point de défaillance ?
Même lorsque les serveurs, les applications et les données restent disponibles, une panne réseau peut suffire à interrompre l’activité. Car un serveur inaccessible à cause du réseau est tout aussi indisponible qu’un serveur en panne. Le réseau constitue donc une couche essentielle de la résilience de votre SI. L’objectif est d’éliminer les points uniques de défaillance et de maintenir les communications entre les utilisateurs, les applications et les données.
Sécuriser l’accès Internet
La connexion Internet est devenue aussi critique que les applications elles-mêmes. Une coupure opérateur peut rapidement impacter les applications SaaS, les services cloud, les communications et les accès distants. Plusieurs mécanismes permettent de réduire ce risque, que la défaillance provienne d’un opérateur ou d’un support physique :
- Double accès Internet ;
- Multi-opérateurs ;
- Technologies d’accès différentes (fibre, xDSL, 4G/5G) ;
- Bascule automatique.
Éliminer les points de défaillance du réseau local
Mais la résilience ne concerne pas uniquement les accès externes. Certains de vos équipements réseau peuvent devenir ce point de défaillance : commutateurs cœur de réseau, contrôleurs Wi-Fi, firewall, routeurs… Plusieurs architectures permettent de limiter ce risque :
- Empilement (stacking) ;
- Châssis virtuels ;
- Paires d’équipements en haute disponibilité ;
- Liens redondants.
Assurer les interconnexions entre sites
Agence, site de production, entrepôt… Lorsque vous avez plusieurs sites, il faut également envisager la rupture de liaison peut complètement en isoler un malgré une infrastructure fonctionnelle. Pour assurer l’interconnexion, les solutions les plus courantes reposent sur :
- Des liaisons redondantes ;
- Plusieurs opérateurs ;
- Des architectures SD-WAN :
- Des mécanismes de routage dynamique.
💡Découvrez le SD-WAN avec notre livre blanc SD-WAN pour les nuls
Superviser pour réagir rapidement
Mais la continuité du réseau ne repose pas uniquement sur la redondance. Vous êtes bien équipés, et prêts à réagir en cas de problème. Encore faut-il le détecter rapidement ! La supervision permet de détecter les défaillances, identifier les saturations, voire même anticiper certaines pannes. En bref, d’accélérer les interventions et donc réduire le temps d’intervention. Une architecture redondée permet d’encaisser certaines pannes. Une supervision efficace permet de les détecter rapidement et d’en limiter l’impact.
📲 Assurer la disponibilité des applications
🎯 Comment maintenir les services critiques malgré la défaillance d’une application ?
La généralisation du SaaS a un impact important sur les plans de continuité et de reprise d’activité. Si l’entreprise n’a plus à gérer directement l’infrastructure sous-jacente, elle reste néanmoins dépendante de la disponibilité des services fournis. L’objectif de cette couche de résilience est donc d’évaluer ces dépendances et d’anticiper les conséquences d’une indisponibilité, qu’elle soit temporaire ou prolongée.
Migrer une application vers le SaaS ne transfère pas automatiquement le risque. Vous devez vous assurer que le fournisseur dispose lui-même des dispositifs nécessaires pour garantir la continuité de ses services. Plusieurs éléments méritent une attention particulière :
- Les engagements de disponibilité (SLA) ;
- La redondance des infrastructures ;
- La répartition géographique des données ;
- Les dispositifs de sauvegarde et de reprise ;
- Les certifications et audits de sécurité ;
- Les mécanismes de continuité d’activité ;
- Les dépendances cachées (services tiers indispensables par exemple).
L’objectif n’est pas nécessairement d’obtenir un niveau de disponibilité maximal, mais de s’assurer que celui proposé est adapté à votre activité.
Il convient également d’envisager le cas où une application est rendue indisponible de façon prolongée, voire définitive (cyberattaque, fermeture du service, faillite du prestataire, changement de stratégie commerciale, etc). Pour pallier à cette situation, vous devez à minima vous assurer que :
- Les données peuvent être exportées dans un format exploitable ;
- Les mécanismes de réversibilité proposés par l’éditeur sont documentés ;
- Des solutions alternatives vers lesquelles vous pourriez migrer « rapidement » existe (dans le cas d’applications critiques).
Nous aborderons cette partie plus en détail dans l’article suivant dédié à l’implication des tiers dans le PRA et le PCA.
💾 Protéger et répliquer les données
🎯 Comment récupérer mes données en cas de sinistre ?
Nous arrivons enfin à l’étape de la sauvegarde !
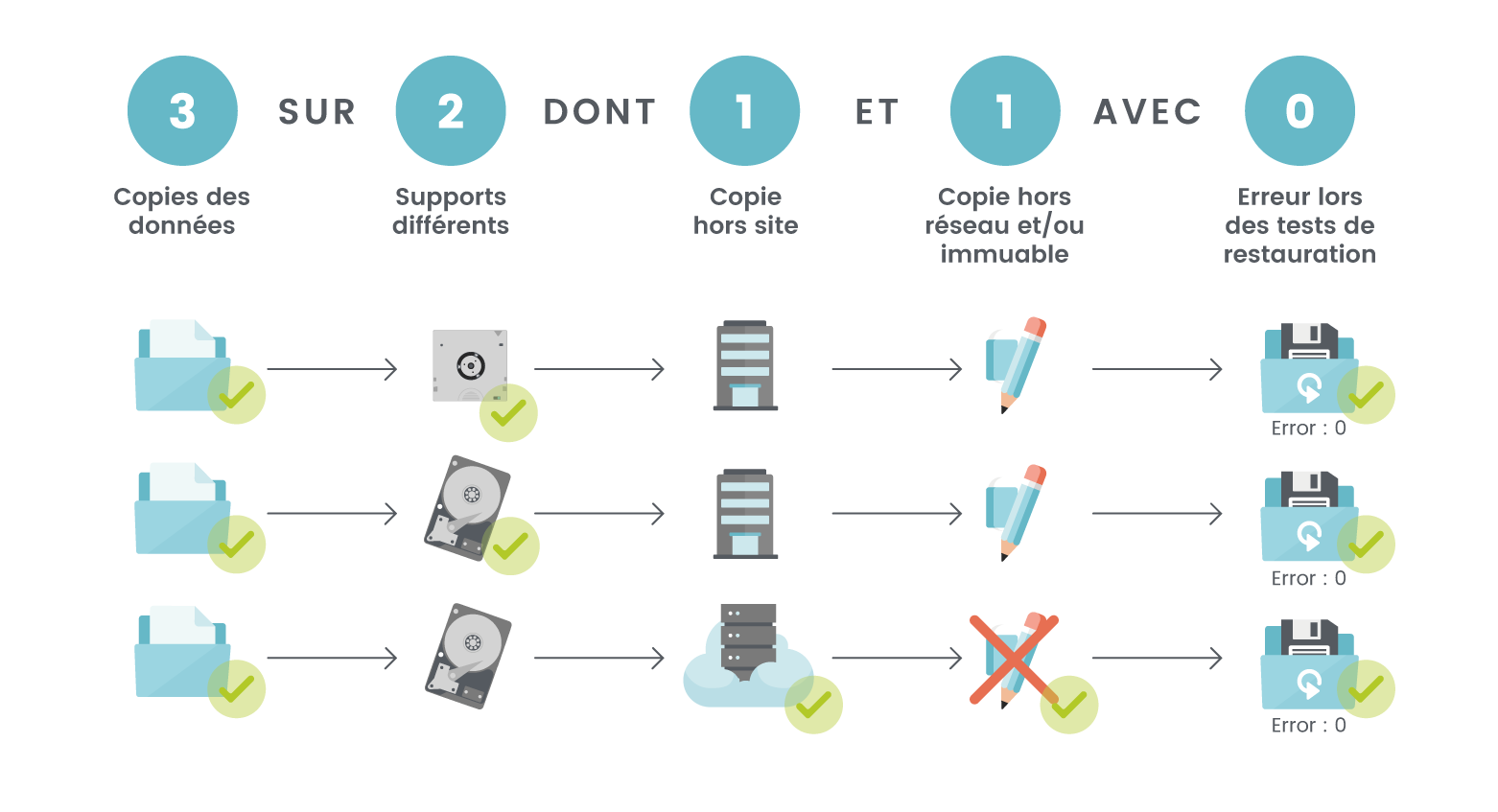
Les données constituent souvent l’actif le plus critique du système d’information. Une infrastructure parfaitement fonctionnelle ne présente que peu d’intérêt si les informations nécessaires à l’activité sont perdues, corrompues ou inaccessibles. Cette couche de résilience vise donc à protéger les données contre les différents scénarios identifiés lors de l’analyse des risques et à garantir leur disponibilité dans les délais définis par les objectifs de reprise. Pour répondre à ces enjeux, de nombreuses organisations s’appuient aujourd’hui sur la stratégie 3-2-1-1-0, qui constitue une référence en matière de protection des données.
💡Je n’entrerai pas dans le détail des supports et types de sauvegarde, mais si vous êtes intéressé, notre libre blanc La sauvegarde au cœur du plan de reprise d’activité vous fournira tout ce que vous avez besoin de savoir à ce sujet !
3 copies de données
La première règle consiste à disposer d’au moins trois copies des données au cas où une des sauvegardes tombe avec les données originales. :
- Les données de production ;
- Une première copie de sauvegarde ;
- Une seconde copie de sauvegarde.
Sur au moins 2 supports différents
Les différentes copies ne doivent pas reposer sur la même technologie ou la même infrastructure.
Par exemple :
- Baie de stockage et stockage objet ;
- Infrastructure locale et Cloud ;
- Disque et bande.
Vous pouvez avoir 5 ou 10 copies de vos données, si elles sont toutes sur le même support, vous les perdrez toutes en cas de défaillance matérielle, logicielle ou opérationnelle !
Dont 1 copie hors site
Conserver toutes les sauvegardes sur le même site revient à les exposer aux mêmes risques. Dans le cas où la salle, le bâtiment, la ville où se trouvent l’ensemble de vos supports est impactée par un sinistre de grande ampleur (incendie, inondation, indisponibilité prolongée…), ils seront tous impactés de la même manière. Une copie doit donc être stockée sur une infrastructure physiquement distincte. Cette externalisation peut être réalisée sur un second site, dans un datacenter distant, dans le Cloud…
Et 1 copie hors ligne ou non modifiable
Les cyberattaques, et notamment les ransomwares, ciblent désormais les sauvegardes autant que les données de production. Les nouvelles stratégies de sauvegarde recommandent donc de disposer d’au moins une copie immuable (les données peuvent être lues mais plus modifiées une fois inscrites) ou isolée (non accessible depuis le réseau). L’objectif est de garantir qu’au moins une sauvegarde reste exploitable même lorsqu’un attaquant parvient à compromettre l’environnement principal.
Il existe différentes solutions pour atteindre cette mesure :
- Stockage immuable ;
- Sauvegarde hors ligne ;
- Coffre-fort numérique ;
- Air gap logique ou physique.
Avec 0 erreur lors des tests de restauration
Cette dernière mesure est souvent négligée. Et pourtant, c’est peut-être le plus important ! Avoir 12 copies de données réparties sur toute la planète n’a aucun intérêt si vous n’êtes pas capable de les restaurer correctement en cas de besoin. Une sauvegarde qui n’a jamais été restaurée reste une hypothèse. Il est donc nécessaire de vérifier que vos sauvegardes sont restaurable sans erreurs, et que vous saurez le faire lorsque la situation l’imposera.
En pratique, cela implique :
- Des contrôles d’intégrité automatisés ;
- Des tests réguliers de restauration ;
- Des instructions de reprise documentées.
Réplication : quand la sauvegarde ne suffit plus
La stratégie 3-2-1-1-0 constitue une excellente base de protection des données. Toutefois, lorsque les objectifs de reprise imposent des RTO ou des RPO très faibles, elle peut être complétée par des mécanismes de réplication permettant de remettre les données à disposition plus rapidement. Si la sauvegarde est au cœur de la stratégie de reprise, la réplication, elle, s’inscrit dans le plan de continuité d’activité. Selon les besoins, plusieurs approches peuvent être envisagées :
- Locale ;
- Vers un site secondaire ;
- Vers le cloud ;
- Synchrone ou asynchrone.
Le choix dépendra principalement des RTO et RPO visés ainsi que de vos contraintes techniques et budgétaires.
👨💻 Maintenir l’activité des utilisateurs
🎯 Comment permettre aux collaborateurs de continuer à travailler malgré un incident ?
La résilience d’un système d’information ne se limite pas à ses infrastructures, à ses réseaux ou à ses données. Pour être efficace, elle doit également permettre aux utilisateurs de poursuivre leurs activités lorsque survient un incident majeur. Cette dernière couche de résilience vise donc à s’assurer que vos collaborateurs disposent des moyens, des connaissances et des procédures nécessaires pour maintenir l’activité dans des conditions dégradées.
Faciliter le travail à distance
L’indisponibilité d’un bâtiment ou d’un site, quelle qu’en soit la raison (travaux, alerte météo, confinement, etc) ne doit pas nécessairement entraîner l’arrêt de l’activité. Pour de nombreuses organisations, le télétravail constitue aujourd’hui une solution efficace pour permettre aux collaborateurs de poursuivre leurs missions même lorsque les locaux habituels deviennent temporairement inaccessibles. Sa mise en œuvre repose notamment sur :
-
Des équipements nomades adaptés ;
-
Des outils collaboratifs accessibles à distance ;
-
Des moyens d’accès sécurisés aux ressources de l’entreprise ;
-
Des procédures permettant aux équipes de basculer rapidement vers un mode de fonctionnement distant.
Sensibiliser les utilisateurs
Ceci est peut-être le plus important pour la réussite de votre PCA PRA. On l’oublie souvent, mais un plan de continuité ne doit pas être découvert le jour où il devient nécessaire.
Les équipes doivent connaître les procédures applicables à leur périmètre, savoir où trouver les informations utiles, comment communiquer, qui contacter et comment réagir en cas d’interruption.
Cette préparation peut notamment passer par :
-
Des guides ou fiches réflexes ;
-
Des exercices de simulation ;
-
Des formations ciblées ;
-
Des communications régulières sur les dispositifs existants.
Il n’est pas nécessaire que chaque collaborateur maitrise vos plans sur le bout des doigts. Mais l’idéal est qu’il ait à disposition un résumé des bons réflexes à avoir lorsque la situation l’exige. Nous en reparlerons plus en détail lors de l’article dédié.
💡Inspirez-vous avec la Boite à Outils de sensibilisation du DSI, et découvrez notre formation aux bonnes pratiques de cybersécurité.
Et voilà pour aujourd’hui ! Comme je le disais au début, il n’y a ni solution miracle, ni processus standard. Vous devez construire votre résilience couche par couche, en combinant les mécanismes les plus adaptés à vos risques, vos objectifs et vos contraintes financières, commerciales et politiques. Mais aussi robuste soit-elle, votre stratégie PCA/PRA reste dépendante d’un facteur sur lequel vous avez rarement la main : les tiers. Prestataires, hébergeurs, fournisseurs cloud ou partenaires peuvent eux aussi devenir des points de défaillance qu’il faut anticiper à défaut de maîtriser. C’est ce que nous aborderons dans le prochain chapitre de cette série.
⏮️ Retournez au 1er article de la série.
◀️ Retrouvez ici le 7ème article sur la définition des RTO et RPO.
Retrouvez ici le 9ème article sur l’implication des tiers dans vos plans. ▶️